TL;DR
Last year our team faced a decision that many engineering organizations are confronting right now: we had a domain-specific NLP task where off-the-shelf models like ChatGPT and Gemini performed adequately but not well enough for production use. The models would hallucinate industry terminology, miss nuances in our regulatory domain, and occasionally produce outputs that were confidently wrong in ways that could have real business consequences. We needed to fine-tune.
Last year our team faced a decision that many engineering organizations are confronting right now: we had a domain-specific NLP task where off-the-shelf models like ChatGPT and Gemini performed adequately but not well enough for production use. The models would hallucinate industry terminology, miss nuances in our regulatory domain, and occasionally produce outputs that were confidently wrong in ways that could have real business consequences. We needed to fine-tune.
This post covers what we learned through the process — the dataset work, the training decisions, the VRAM headaches, and the deployment architecture that eventually made it all work.
When Fine-Tuning Is the Right Call
Before you reach for fine-tuning, make sure you have actually exhausted the cheaper alternatives. Prompt engineering with few-shot examples can get you surprisingly far. RAG pipelines (which I covered in Building Production-Ready RAG Pipelines with LangChain) solve the knowledge freshness problem without touching model weights. Fine-tuning is the right tool when:
- Your task requires a specific output format or style that prompting alone cannot reliably produce
- Domain-specific jargon and reasoning patterns are consistently mishandled by general models
- You need to reduce inference costs by using a smaller, specialized model instead of a large general one
- Latency requirements demand a smaller model that runs on your own infrastructure
For us, the trigger was the third point. We were spending $15K per month on GPT-4 API calls for a document classification and extraction pipeline. A fine-tuned Llama 2 7B model running on our own GPU nodes handled the same task at a fraction of the cost, with better accuracy on our specific document types.
Dataset Preparation: The 80% of the Work
I cannot overstate how much of the fine-tuning effort goes into data preparation. We spent three weeks on model training and eight weeks on building and cleaning the dataset. Here is the process that worked for us.
Step 1: Collect and Structure Raw Data
We started with 50,000 documents from our production database. These were compliance reports that needed to be classified into 23 categories and have key entities extracted. We exported them with their existing (human-assigned) labels:
import pandas as pd
from datasets import Dataset
# Load raw labeled data
df = pd.read_parquet("compliance_docs_labeled.parquet")
print(f"Total documents: {len(df)}")
print(f"Label distribution:\n{df['category'].value_counts()}")
# Convert to instruction-following format
def format_as_instruction(row):
return {
"instruction": (
"Classify the following compliance document into one of "
"the 23 predefined categories and extract key entities "
"(dates, parties, regulation references, and amounts)."
),
"input": row["document_text"][:4096], # Truncate to context window
"output": format_structured_output(
category=row["category"],
entities=row["extracted_entities"]
),
}
formatted = df.apply(format_as_instruction, axis=1, result_type="expand")
dataset = Dataset.from_pandas(formatted)
Step 2: Clean and Deduplicate
Raw production data is messy. We found duplicate documents, mislabeled examples, and edge cases where the human labels were inconsistent. We built a deduplication pipeline using MinHash LSH for near-duplicate detection:
from datasketch import MinHash, MinHashLSH
lsh = MinHashLSH(threshold=0.85, num_perm=128)
duplicates = set()
for idx, text in enumerate(df["document_text"]):
minhash = MinHash(num_perm=128)
for word in text.split():
minhash.update(word.encode("utf-8"))
result = lsh.query(minhash)
if result:
duplicates.add(idx)
else:
lsh.insert(idx, minhash)
print(f"Found {len(duplicates)} near-duplicates out of {len(df)} documents")
# Found 4,832 near-duplicates out of 50,000 documents
Nearly 10% of our dataset was near-duplicate content. Training on that would have biased the model toward overrepresented document types.
Step 3: Balance and Split
Our category distribution was heavily skewed — the top 3 categories accounted for 60% of all documents. We used a combination of oversampling minority classes and undersampling majority classes to create a more balanced training set, while keeping the validation set at natural distribution to get realistic performance metrics.
from sklearn.model_selection import train_test_split
# Stratified split preserving category distribution
train_df, val_df = train_test_split(
clean_df, test_size=0.15, stratify=clean_df["category"], random_state=42
)
# Balance training set
balanced_train = balance_dataset(
train_df,
target_col="category",
strategy="hybrid", # Oversample minority, undersample majority
min_samples=200,
max_samples=2000,
)
print(f"Training samples: {len(balanced_train)}")
print(f"Validation samples: {len(val_df)}")
# Training samples: 28,400
# Validation samples: 6,775
Choosing the Base Model
We evaluated several base models before settling on our approach:
| Model | Parameters | Performance on Our Eval | Inference Cost |
|---|---|---|---|
| GPT-4 (API) | Unknown | 91.2% accuracy | $15K/month |
| GPT-3.5 Turbo (API) | Unknown | 78.4% accuracy | $2K/month |
| Llama 2 7B | 7B | 64.1% (base) | Self-hosted |
| Llama 2 13B | 13B | 69.8% (base) | Self-hosted |
| Mistral 7B | 7B | 71.3% (base) | Self-hosted |
The base model accuracy numbers were from zero-shot evaluation. The question was whether fine-tuning could close the gap between Mistral 7B's 71.3% and GPT-4's 91.2%. Spoiler: after fine-tuning, our Mistral 7B model hit 93.7% on the same eval set — actually exceeding GPT-4 on our specific task.
Training: QLoRA and VRAM Optimization
Fine-tuning a 7B parameter model on full precision would require roughly 28GB of VRAM just for the model weights, plus optimizer states and gradients. We used QLoRA (Quantized Low-Rank Adaptation) through Hugging Face's PEFT library, which let us fine-tune on a single A100 40GB GPU:
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from trl import SFTTrainer
# 4-bit quantization config for VRAM optimization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1",
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model = prepare_model_for_kbit_training(model)
# LoRA configuration — target attention layers
lora_config = LoraConfig(
r=64,
lora_alpha=128,
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, lora_config)
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
print(f"Trainable: {trainable_params:,} / {total_params:,} "
f"({100 * trainable_params / total_params:.2f}%)")
# Trainable: 83,886,080 / 7,325,908,992 (1.15%)
We are only training 1.15% of the model's parameters. The 4-bit quantization brings VRAM usage down to about 12GB for the model, leaving headroom for batch processing. A few key decisions here:
LoRA rank (r=64): We started at r=16 which is common in tutorials, but our task complexity required more capacity. We swept r across and found that 64 gave the best tradeoff between performance and training speed. Going to 128 gave marginal improvement at 2x the training time.
Target modules: Including the MLP projection layers (gate_proj, up_proj, down_proj) in addition to the attention layers gave us a 3% accuracy boost. Many tutorials only target attention — do not overlook the MLP layers for domain adaptation.
Training Configuration
training_args = TrainingArguments(
output_dir="./compliance-mistral-7b",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=8, # Effective batch size: 32
learning_rate=2e-4,
weight_decay=0.01,
warmup_ratio=0.05,
lr_scheduler_type="cosine",
logging_steps=25,
save_strategy="steps",
save_steps=200,
eval_strategy="steps",
eval_steps=200,
bf16=True,
optim="paged_adamw_8bit",
gradient_checkpointing=True,
max_grad_norm=0.3,
report_to="wandb",
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=tokenizer,
max_seq_length=4096,
dataset_text_field="text",
)
trainer.train()
A few VRAM optimization techniques that made the difference between fitting on one GPU and needing two:
- Gradient checkpointing trades compute for memory by recomputing activations during the backward pass instead of storing them. This reduced VRAM usage by about 30%.
- Paged AdamW 8-bit optimizer from bitsandbytes keeps optimizer states in 8-bit precision and pages to CPU RAM when GPU memory is tight.
- Gradient accumulation lets us simulate a batch size of 32 while only processing 4 samples at a time on the GPU.
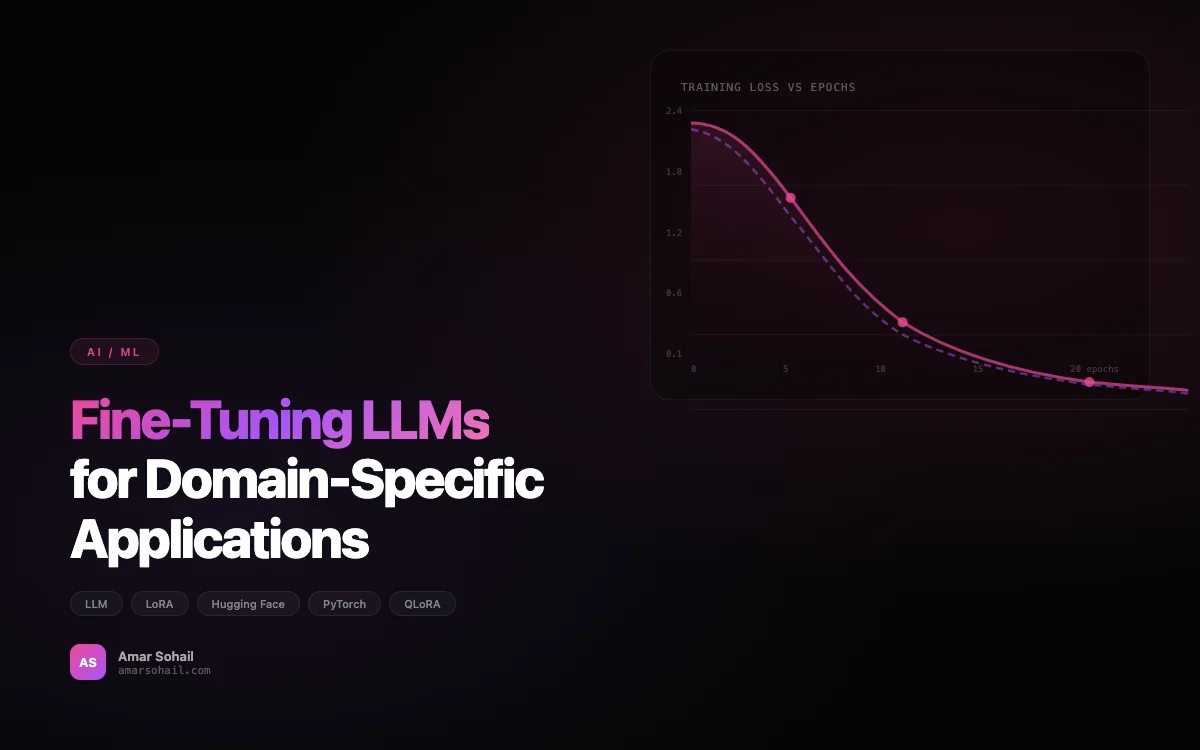
Total training time: approximately 6 hours on a single A100 40GB for 3 epochs over 28,400 training samples.
Evaluation Beyond Accuracy
Raw accuracy is not enough. We built an evaluation suite that measures:
from sklearn.metrics import classification_report, confusion_matrix
import numpy as np
def evaluate_model(model, tokenizer, eval_dataset):
predictions = []
references = []
for sample in eval_dataset:
output = generate_prediction(model, tokenizer, sample["input"])
pred_category = parse_category(output)
pred_entities = parse_entities(output)
predictions.append(pred_category)
references.append(sample["expected_category"])
report = classification_report(
references, predictions, output_dict=True
)
# Check for hallucinated categories
valid_categories = set(CATEGORY_LIST)
hallucinated = sum(
1 for p in predictions if p not in valid_categories
)
return {
"accuracy": report["accuracy"],
"macro_f1": report["macro avg"]["f1-score"],
"hallucinated_categories": hallucinated / len(predictions),
"per_class_f1": {k: v["f1-score"] for k, v in report.items()
if k not in ["accuracy", "macro avg", "weighted avg"]},
}
Our fine-tuned model achieved:
- 93.7% classification accuracy (up from 71.3% base Mistral, beating GPT-4's 91.2%)
- 0.2% hallucination rate on category names (down from 8.4% for the base model)
- 91.1% entity extraction F1 (compared to GPT-4's 89.3%)
The hallucination rate metric is one that people overlook. A base model will sometimes invent categories that do not exist in your taxonomy. Fine-tuning essentially eliminates this.
Model Deployment with MLOps
We deploy the fine-tuned model using vLLM behind a FastAPI service, running on the GPU nodes in our Kubernetes cluster (the same infrastructure I described in Kubernetes at Scale):
from vllm import LLM, SamplingParams
# Merge LoRA weights with base model for inference
merged_model_path = "./compliance-mistral-7b-merged"
llm = LLM(
model=merged_model_path,
tensor_parallel_size=1,
gpu_memory_utilization=0.85,
max_model_len=4096,
quantization="awq", # Use AWQ for inference quantization
)
sampling_params = SamplingParams(
temperature=0.1,
max_tokens=1024,
top_p=0.95,
)
We use AWQ quantization for inference (separate from the QLoRA training quantization) which gives us 4-bit inference with minimal quality loss. This means the model runs comfortably on a single T4 GPU in production — a $0.526/hour instance on AWS, compared to $15K/month for GPT-4 API calls. The monthly inference cost for the same workload is approximately $400.
The MLOps Pipeline
Model deployment is not a one-time event. We retrain monthly as new labeled data comes in, and we need a pipeline that handles the full lifecycle:
- Data pipeline: New labeled documents flow from production into our training data lake nightly
- Training trigger: When we accumulate 1000+ new labeled samples, a training run kicks off automatically
- Evaluation gate: The new model must beat the current production model on our eval set by at least 0.5% accuracy, or the deployment is blocked
- Shadow deployment: The new model runs alongside the current one for 48 hours, processing the same requests. We compare outputs and flag any regressions
- Promotion: If shadow testing passes, the new model replaces the current one via a rolling update
We manage this through a combination of Airflow for orchestration and MLflow for experiment tracking and model registry.
Lessons from the Trenches
PyTorch over TensorFlow for LLM work. This is not a philosophical preference — the Hugging Face ecosystem, QLoRA, PEFT, and most LLM tooling is PyTorch-first. We initially tried to use TensorFlow for parts of the pipeline because our team had more experience with it, and we wasted two weeks fighting compatibility issues. The PyTorch ecosystem for LLM fine-tuning is simply more mature.
Data quality trumps data quantity. We saw better results from 15,000 high-quality, deduplicated, well-labeled examples than from 45,000 noisy ones. If you have budget to spend, spend it on data cleaning and labeling quality, not on collecting more data.
Monitor for distribution shift. Our model's accuracy degraded from 93.7% to 88.1% over four months because the types of documents we were processing shifted. The monthly retraining pipeline caught this before it became a customer-facing problem, but it reinforced why continuous evaluation is essential.
Start with the smallest model that works. We almost defaulted to a 13B model because "bigger is better." The 7B model with proper fine-tuning outperformed the 13B base model, and it runs on cheaper hardware. Always benchmark the smaller option first.
Keep a human in the loop. For our compliance use case, we route low-confidence predictions (where the model's top probability is below 0.85) to a human reviewer. This catches the roughly 6% of cases where the model is uncertain, and those human corrections feed back into the next training cycle.
Fine-tuning LLMs is rapidly becoming a core engineering capability rather than a research novelty. The tools from Hugging Face, the quantization techniques for VRAM optimization, and the serving infrastructure like vLLM have matured to the point where a small team can go from idea to production model in weeks, not months. The bottleneck is almost always the data, not the model. Start there.